
 内存管理
内存管理
# linux进程的内存分布
虚拟地址空间被分为内核空间和用户空间,内核空间位于高地址
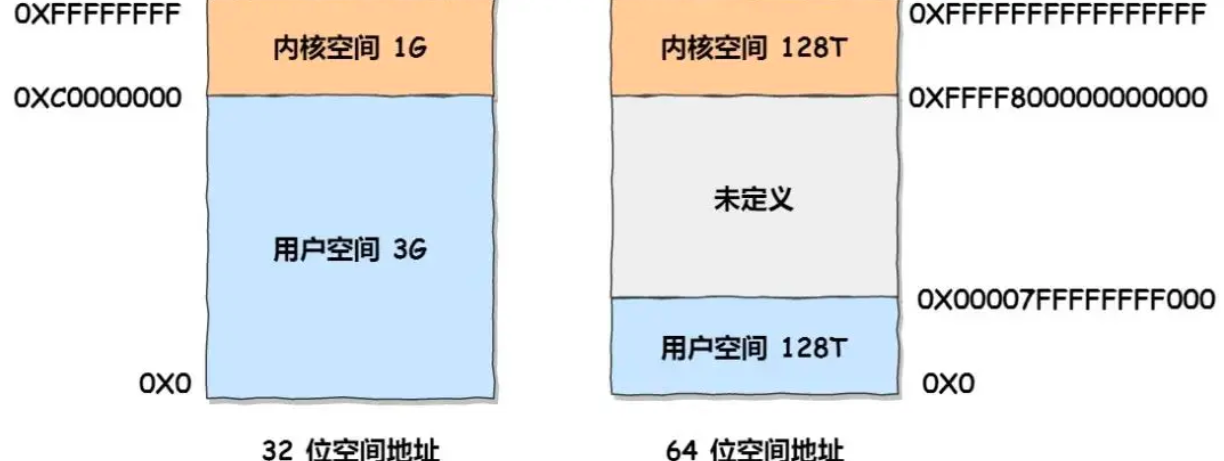
- 32位内核空间占用1G,位于最高处,剩下的3G是用户空间
- 64位内核空间和用户空间都是128T,中间部分未定义
32位的用户空间划分,栈区位于高地址

64位的用户空间划分,64MB的保留区

代码段和数据段中间的不可访问段是为了防止查询在读写数据段时越界访问到代码段,这个保护段可以让越界访问行为崩溃
- 代码段,包括二进制可执行代码
- 数据段,包括已初始化的静态常量和全局变量
- BSS段,包括未初始化的静态变量和全局变量,实际上存放的是未初始化全局变量的内存大小信息
- 堆段,动态分配的内存,从低地址向上增长
- 文件映射段,包括动态库、共享内存,从低地址向上增长
- 栈,包括局部变量和函数调用的上下文等,栈的大小一般固定为8MB
ulimit-s查看
@ 之所以区分BSS段和数据段
BSS段存放的未初始化的数据,因为默认都是0值,因此不需要一一存放它的值,在可执行文件中并不占用存储空间,只记录变量名称和大小,在程序加载到内存中时,再问他们分配内存并初始化为0。从而减少可执行文件的大小
数据段存放已初始化的静态变量和全局变量,这些变量在编译节点就分配了存储空间,在可执行文件中存储了他们的具体值,加载内存时,数据段会将这些变量的具体值拷贝到内存中
# malloc如何分配内存的
# 内存分配的过程
malloc分配内存时申请到虚拟内存,并不会分配物理内存,当应用程序读写了这个虚拟内存,CPU区访问这个虚拟内存,就会产生缺页中断,陷入内核态,缺页中断处理函数会看是否有空闲的物理内存,如果有就分配并建立映射关系,如果没有就作回收内存的工作
# 申请的地址位置
malloc申请内存的时候通过两种方式向操作系统申请堆内存:
方式一:brk()系统调用从堆分配内存
通过brk()函数将堆顶指针向高地址移动,获得新的内存空间
方式二:mmap()系统调用在文件映射区域分配内存
私有匿名映射,在文件映射区分配一块内存
如果用户分配的内存小于128KB,通过brk申请内存,如果用户分配的内存大于128KB,通过mmap申请内存(不同glibc版本不同)
# malloc执行虚拟内存映射到物理内存
malloc分配的内存是虚拟内存,如果这个虚拟内存没有被访问则不会映射到物理内存,不会占用物理内存
只有在访问已分配的虚拟地址空间时,操作系统通过查找页表,发现虚拟内存对应的页不再物理内存中,就会触发缺页中断,然后建立虚拟地址和物理内存的映射关系
# malloc(1)会分配多大的虚拟内存
和分配的内存管理器有关,内存管理器Ptmalloc2为例
/proc路径下是程序运行时的文件,里面的文件名对应运行的进程号
cat /proc/3191/maps : 查看3191这个进程的内存信息,当程序结束这个文件就会立即删除
一个实验来分析这个问题
#include <stdio.h>
#include <malloc.h>
int main() {
printf("使用cat /proc/%d/maps查看内存分配\n",getpid());
//申请1字节的内存
void *addr = malloc(1);
printf("此1字节的内存起始地址:%x\n", addr);
printf("使用cat /proc/%d/maps查看内存分配\n",getpid());
//将程序阻塞
pause();
//释放内存
free(addr);
return 0;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
执行该程序然后查看linux进程文件
[root@xiaolin ~]# cat /proc/3191/maps | grep d730
00d73000-00d94000 rw-p 00000000 00:00 0 [heap]
2
可以看到堆空间的内存地址是00d73000-00d94000,大小为132KB
内存右边没有heap标识表示是以mmap匿名映射的方式从文件映射区分配的匿名内存
程序打印的内存起始是d73010,实际显示的地址起始是d73000,多出了16字节,用于放内存块的描述信息
# free释放内存
针对malloc通过brk()方式申请的内存,直接free后,堆内存还是存在的,并没有归还给操作系统,因为与其把1字节释放给os,不如缓存这放进malloc的内存池里,但再申请时就可以复用
如果是malloc通过mmap方式申请的内存,free释放内存后就会归还给操作系统。将上诉实验改为申请128KB的内存就能验证(free掉后,maps文件里没有这个地址的记录了)
@ free如何知道释放的内存块的大小
内存块前16KB保存了该内存块的描述信息,包括内存块的大小,这样每次释放时,free会将传入的内存地址向左偏移16字节,再分析处当前内存块的大小
# brk方式和mmap方式申请内存的优缺
对于mmap方式
- mmap是系统调用,有内核和用户态切换的开销
- mmap分配的内存每次释放时都会归还给操作系统,于是每次mmap分配都是缺页状态触发缺页中断(一开始分配的虚拟地址,访问时映射物理地址从而触发缺页中断)
对于brk方式
brk()系统调用申请空间时,因为堆空间是连续的,所以直接预分配更大的内存来作为内存池,内存释放时缓存在内存池中,这样减少了缺页中断和系统调用的次数
brk()的问题是对于频繁地malloc和free申请释放小块内存,如果申请的大小递增,之前free释放的内存池不够,就需要新申请,这样频繁进行,就会导致内存泄漏,且无法用valgrind检测出现
# 系统内存紧张
# 当内存紧张时
- 后台内存回收:物理内存紧张时,会唤醒kswapd内核线程来异步回收内存
- 直接内存回收:后台异步回收跟不上进程内存申请的速度,就会开始直接回收,阻塞进程的执行
- 如果直接内存回收后依然无法满足物理内存的申请,就会触发OOM机制(Out Of Memory)
OOM killer机制会根据算法选择一个占用物理内存较高的进程,将其杀死,如果物理内存依然不足会继续下去
# 哪些内存可以被回收
文件页:内核缓存的磁盘数据和内核缓存的文件数据,这些数据都可以直接释放,下次需要再从磁盘读就行(被修改过的脏页需要写回磁盘再释放内存)
匿名页:没有实际载体,如堆栈数据,且通常还需要再次访问,所以不能直接释放,而是通过linux的swap机制。将不常访问的内存写入磁盘中,然后释放给其他进程使用,需要访问时再从磁盘写入
两者的回收都是基于LRU算法,其中维护了active(活跃内存链表)和inactive(不活跃内存链表)两个双向链表
可以从/proc/meminfo中查询他们大小
# grep表示只保留包含active的指标(忽略大小写)
# sort表示按照字母顺序排序
[root@xiaolin ~]# cat /proc/meminfo | grep -i active | sort
Active: 901456 kB
Active(anon): 227252 kB
Active(file): 674204 kB
Inactive: 226232 kB
Inactive(anon): 41948 kB
Inactive(file): 184284 kB
2
3
4
5
6
7
8
9
# 回收内存带来的性能问题
文件页的回收,干净页直接释放不会有性能问题,脏页因为要写回磁盘影响性能
匿名页的回收,swap将匿名页换出磁盘,影响性能
# 调整文件页和匿名页的回收倾向
/proc/sys/vm/swappiness,可以调整文件页和匿名页的回收倾向,0-100,数值越小,越少的使用swap更多的使用回收文件页
通常文件页的回收因为有干净页,整体耗时更小
# 尽早触发kswapd内核线程异步回收内存
查看系统的直接内存回收和后台内存回收的指标
sar -B 1 命令

- pgscank/s表示kswapd线程每秒扫描的page个数
- pgscand/s表示应用程序在内存申请过程中每秒直接扫描的page个数
- pgsteal/s表示扫描的page中每秒被回收的个数
如果系统时不时发生抖动,且pgscand数值很大
# 如何触发kswapd内核线程回收内存
衡量当前剩余内存通过三个内存阔值(水位):
- 页最小阔值(pages_min)
- 页最低阔值(pages_low)
- 页高阔值(pages_high),

页最低阔值以下时会触发内存回收kswapd线程,不会阻塞应用程序,直到剩余内存高于页低阔值。如果剩余内存小于页最小阔值,触发直接内存回收,阻塞应用程序,不会执行kswapd线程
# 查看页最小阔值
/proc/sys/vm/min_free_kbytes # 67584
# pages_low = pages_min * 5/4
# pages_high = pages_min * 3/2
2
3
4
如果系统发生抖动,且pgscand数值很大,那可能是直接内存回收导致的,可以增大min_free_kbytes来更早的触发后台回收
增加min_free_kbytes会使得系统预留更多空闲内存,一定程序上降低了应用程序可使用的内存量,一定程度上浪费了内存。
因此,如果应用程序更关注延迟,就适当增大min_free_kbytes,如果关注内存使用量,就调小
# NUMA架构下的内存回收策略
SMP架构指多个CPU共享资源的硬件架构,每个CPU地位平等,也称为一致存储访问结构,缺点是多个CPU通过一个总线访问内存使得总线压力变大
NUMA架构,非一致存储访问结构,对多个CPU分组为多个node,node和CPU是一对多,每个node有自己独立的资源,内存,IO,且可通过互联模块总线通信,访问远端的node耗时更大
NUMA下,当Node内存不足时,系统可以从其他node寻找空闲内存,也可以从本地内存中回收内存
可以通过/proc/sys/vm/zone_reclaim_mode来控制
- 0(默认):在回收本地内存前,在其他node寻找空闲空间
- 1:只回收本地内存
- 2:只回收本地内存,可以将脏页写回硬盘
- 3:只回收本地内存,可以用swap方式回收内存
NUMA架构的服务中,如果系统还有一半内存却频繁触发直接内存回收,可能是zone_reclaim_mode没有设置为0。访问远端node带来的性能问题小于内存回收的危害
# 如何保证一个进程不被OOM杀掉
选择进程杀掉的标准:
oom_badness函数会把系统中可以杀掉的进程扫描一遍并对其打分,得分最高的进程会被杀掉
# process_pages代表进程已经使用的物理内存页面数
# 代表OOM校准值,所以进程默认为0
# 代表系统总的可用页面数
points = process_pages + oom_score_adj*totalpages/1000
# 因此通常还是由进程使用的页面数来决定的
2
3
4
5
我们可用调整oom_score_adj的数值来修改进程的得分结果,将oom_score_adj配置为-1000使得其无法被杀掉,例如
# 4GB物理内存的机器上申请8GB内存

对于32位系统最大只能申请3GB大小的虚拟内存空间,因此无法申请
对于64位系统的申请请求,取决于/proc/sys/vm/overcommit_memory参数
- 0(默认值):内核利用某种算法猜测你的内存申请是否合理,超过了就会拒绝
- 1:允许申请
- 2:拒绝申请
申请通过后,还要看实际物理内存大小,每次申请虽然还不会映射到物理内存,但保存虚拟内存的数据结构也占物理内存,2GB机器上申请128TB的内存申请到一定大小就会被杀死
如果开启swap,可以申请127.997TB的空间,还有一部分申请不到,因为程序自身也需要空间
这里是申请,而真正访问,则取决于swap机制
# Swap机制
上诉主要是虚拟内存不够时的方案,对于物理内存不够,就需要将物理内存中的一部分临时保存到磁盘,等这些程序要运行时再从磁盘中恢复到内存中
使用swap机制使得实际使用的内存空间远超系统的物理内存,但缺点是频繁的读写硬盘会降低操作系统的运行速率
触发场景:
- 内存不足:直接内存回收,阻塞当前申请内存,将不常用的内存也交换到磁盘上
- 内存闲置:当空闲内存低于一定水位时,回收空闲内存保证其他进程可以尽快获得申请的内存,kswapd后台线程异步完成
linux有两种方式启用Swap:
- Swap分区:在硬盘上开启独立区域,只用于分区交换,不能存储其他文件,
swapon -s命令查看当前系统上的交换分区 - Swap文件:文件系统的特殊文件,和其他文件没有太多区别
@ 不开启swap,2GB的物理内存访问4GB
会被系统杀掉,报错内存溢出OOM,即系统中存在无法回收的内存或使用的内存过多
@ 开启swap,8GB的物理内存访问64GB
对于50GB左右的内存可以正常访问,再往上涨当系统多次尝试回收内存依然无法满足所需使用的内存大小,就会杀掉进程
# 缓存设计
mysql和linux都使用改进的LRU来实现缓存
@ LRU预读失效
mysql和linux都划分了2个区域,将数据分为冷数据和热数据,分别进行LRU算法
linux中,预读数据加入非活跃链表头部,当页真正被访问时才插入活跃链表头部,和mysql差不多
@ LRU缓存污染
linux中,当内存页被第二次访问时,才将页从非活跃链表升级到活跃链表中
mysql中,再次被访问,且在old区域的停留时间在1s以上才升级到young区域
# 进程虚拟内存空间的管理
# 进程结构
进程在内核中的描述结构PCB
struct task_struct {
// 进程id
pid_t pid;
// 用于标识线程所属的进程 pid
pid_t tgid;
// 进程打开的文件信息
struct files_struct *files;
// 内存描述符表示进程虚拟地址空间
struct mm_struct *mm;
.......... 省略 .......
}
2
3
4
5
6
7
8
9
10
11
12
在创建进程PCB时,通过fork创建的子进程是直接继承拷贝父进程的mm_struct进程虚拟地址空间,
通过vfork或者clone系统创建出来的子进程,父子进程的虚拟内存空间变为共享的,增加引用计数器,即线程
内核线程和用户态线程的区别就是内核线程没有相关的内存描述符mm_struct,内核线程的这个指向null
内核线程调度时发现自己的虚拟地址空间为null,直接复用上一个用户态进程的虚拟内存空间mm_struct,内核线程和用户线程不会访问对方的空间,因此和上一个用户级线程共用一个mm_struct。可以避免为内核线程分配mm_struct和相关页表的开销,避免内核线程间调度时的切换地址空间的开销
# 内存空间结构
mm_struct中的task_size变量定义了用户态地址空间和内核态地址空间的分界线
64位下,进程的mm_struct结构中的task_size为0X0000 7FFF FFFF F000
struct mm_struct {
unsigned long task_size; //定义了用户态地址空间和内核态地址空间的分界线
unsigned long start_code, end_code, //定义代码段的起始和结束位置
start_data, end_data;//定义数据段的起始和结束位置
unsigned long start_brk, brk, //定义堆的起始位置,brk定义堆的结束位置
start_stack;//start_stack是栈的起始位置,stack pointer是栈顶指针
unsigned long arg_start, arg_end, //arg_start、arg_end是栈中参数列表的位置
env_start, env_end;//env_start和env_end是栈中环境变量的位置
unsigned long mmap_base; //内存映射区的起始地址
unsigned long total_vm; //表示虚拟内存空间建立了映射的页数量,不是真正分配物理内存
unsigned long locked_vm; //表示内存吃紧下,被锁定不能换出的内存页总数
unsigned long pinned_vm; //表示既不能换出,也不能移动的内存使用情况
unsigned long data_vm; //表示数据段中映射的内存页数目,描述内存使用情况
unsigned long exec_vm; //代码段中存放可执行文件的内存页数目
unsigned long stack_vm; //栈中映射的内存页数目
...... 省略 ........
struct vm_area_struct* mmap; //管理所有的内存区
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
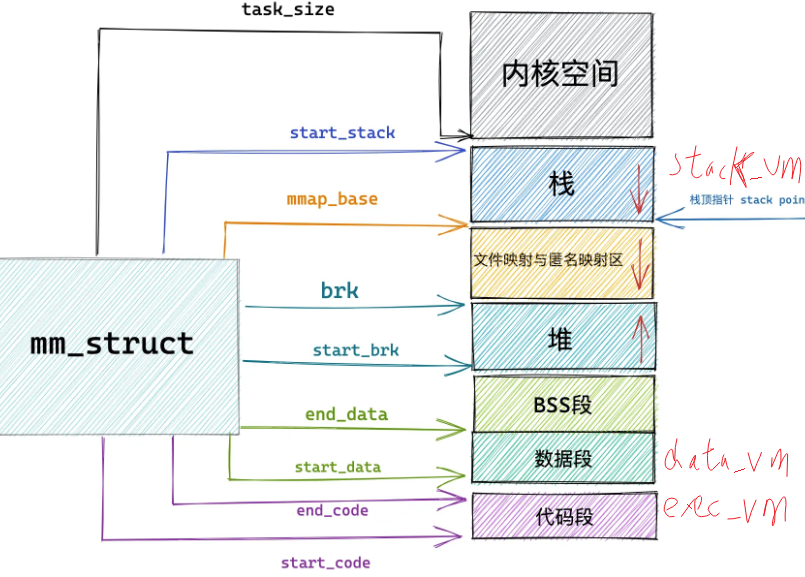
BBS段大小固定
映射到物理内存上位匿名映射,映射到文件中为文件映射
# 内存区域结构
具体一个虚拟内存区域的管理
struct vm_area_struct{
unsigned long vm_start, vm_end;//这块区域的起始地址、结束地址,左闭右开
pgprot_t vm_page_prot;//对物理页的访问权限
unsigned long vm_flags; //整个虚拟内存的访问权限和行为规范
struct anon_vma *anon_vma;//VMA内存区域,管理申请的超过128k的内存
struct file * vm_file;//关联被映射的文件
unsigned long vm_pgoff; //映射的文件的频移量
void * vm_private_data;//存储VMA中的私有数据
struct vm_area_struct *vm_next, *vm_prev;//双向链表的前驱和后继节点
const struct vm_operations_struct *vm_ops;//对这个结构体操作的函数指针
}
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);//虚拟内存加入到内存空间时
void (*close)(struct vm_area_struct * area);//删除
vm_fault_t (*fault)(struct vm_fault *vmf);//缺页时调用
vm_fault_t (*page_mkwrite)(struct vm_fault *vmf);//可读变为可写时调用
..... 省略 .......
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
vm_flags关键字定义了对当前空间的访问权限
- 代码段:可读、可执行、不可写
- 数据段:可读、可写、不可执行
- 堆:可读、可写、可执行(java字节码)
- 栈:可读、可写
- 文件映射和匿名映射区:可读、可写、可执行
vm_flags关键字其他可以关注的类型:
- VM_SHARD:是否多进程共享
- VM_IO:表示这块虚拟内存区域可以映射设备IO空间
- VM_RESERVED:不可换出
- VM_SEQ_READ: 暗示内核,应用程序对这块虚拟内存区域是否采用顺序读
- VM_RAND_READ:暗示内核,应用程序会对这块区域进行随机读取
# 内存区域如何组织
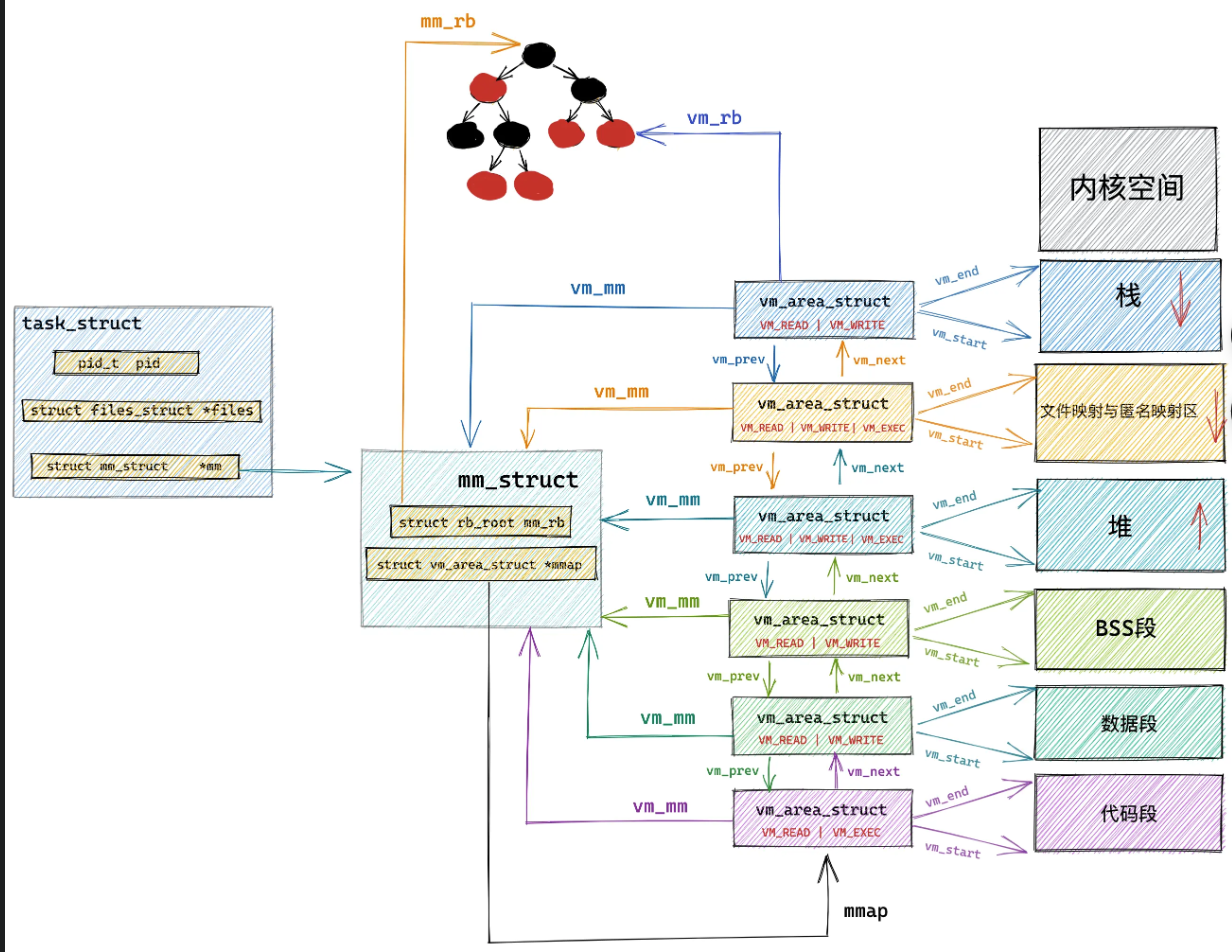
通过cat /proc/pid/maps或者pmap pid 查看进程的内存信息,就是通过遍历vm_area_struct这个双向链表来实现
vm_area_struc在内核中有两种方式组织,一是双向链表,二是红黑树。
# 程序编译后的二进制文件如何映射到虚拟内存空间
程序编译后生成ELF格式的二进制文件,其中的布局类似虚拟内存空间的布局,每一区对应不同的元数据。多区映射到一个内存段中
static int load_elf_binary(struct linux_binprm *bprm){
//设置虚拟内存空间中的内存映射区起始地址
setup_new_exec(bprm);
//创建并初始化栈对应的vm_area_struct结构,设置起始地址
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
//将二进制文件中的代码部分映射到虚拟内存空间中
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, total_size);
//创建并初始化堆vm_area_struct结构,设置起始地址
……
retval = set_brk(elf_bss, elf_brk, bss_prot);
//映射依赖的动态库
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias, interp_elf_phdata);
//初始化内存描述符mm_struct
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 内核虚拟内存空间
int* a;
a=(int*)(0x7ffd55147b80);//随便写一个
int *b = new (a)int(1);//段错误,a的地址空间不属于这个程序
2
3
内核内存依然是虚拟地址空间
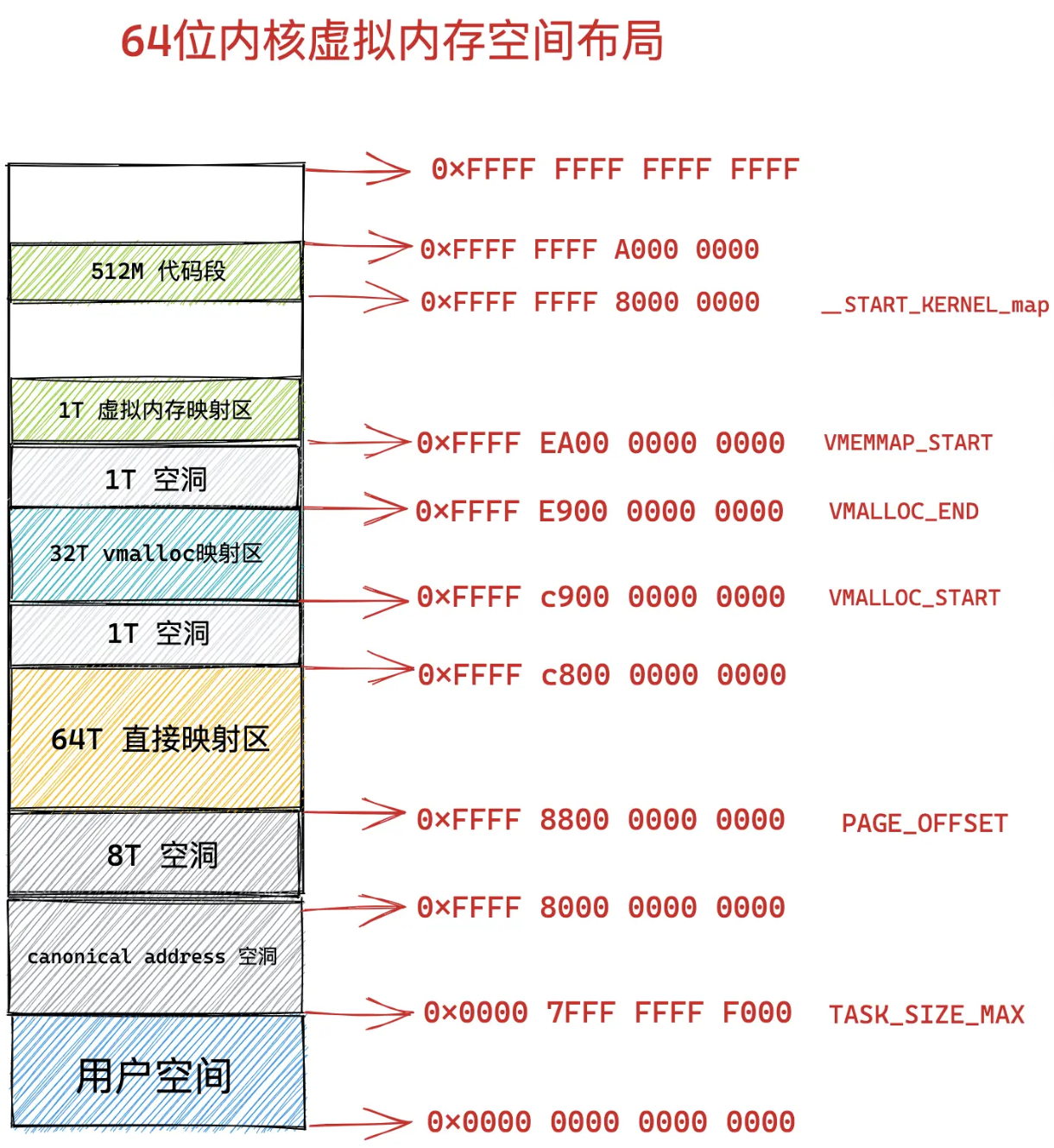
直接映射区内的内存地址减去PAGE_OFFSET就直接得到了物理内存地址,
定义在 /arch/x86/include/asm/page_64_types.h 文件中
vmalloc映射区,内核在这里使用vmalloc系统调用申请内存
1T的虚拟内存映射区,存放物理页面的描述符结构struct page
512M的代码段,存放内核代码段、全局遍历、BBS等,减去 __START_KERNEL_map 就能得到物理内存的地址。与直接映射区不冲突

