
 redis原理
redis原理
# redis概述
# 简介
是一种内存数据结构存储,用作数据库、缓存、消息代理、流引擎
redis作为msql的缓存,因为其有高性能和高并发
特点
- 定期将数据转到磁盘持久化,也可以关闭这个功能
- 支持多种数据结构并对其运行原子操作:
- 基于内存的数据库,读写操作在内存中完成,读写速度很快
- 支持事务 、持久化、Lua 脚本、多种集群方案(主从复制模式、哨兵模式、切片机群模式)、发布/订阅模式,内存淘汰机制、过期删除机制等等
redis和etcd
redis有更好的查询性能,支持更多的数据结果 etcd更为可靠安全,故障转移和持续数据可用,数据均持久化
redis和memcached
共同点: 两者都是基于内存的数据库,作为缓存使用,有极高的性能 都有过期策略
区别:
- redis支持更多数据类型,memcached是kv数据类型
- redis有持久化功能,memcached没有
- redis支持集群模式,memcached没有原生的集群模式
- redis支持发布订阅模型、lua脚本、事务等功能,memcached不支持
# 数据结构
redis的所有对象都用redisObject保存
struct redisObject{
unsigned type:4;//对象的类型
unsigned encoding:4;//具体的编码方式,embstr、sds
unsigned lru:LRU_BITS;//24位,表示对象最后一次被程序访问的时间,和内存回收有关
int refcount;//引用计数,4字节
void *ptr;//指向对象实际的数据结构,8字节
}//总共16字节
2
3
4
5
6
7
redis整体上是一个键值对数据库,非关系型数据库
key为字符串对象,value可以是string、list、hash、set、zset
SET name "redis"# 键为name,值为redis,string类型
HSET person name "redis" age 18 # 哈希表键,键为person,值为两个键值对
RPUSH stu "redis" "01" # 列表键,键为stu,值是一个包含两个元素的列表对象
2
3
对于这些键值对,redis统一使用哈希表来保存所有键值对,一个哈希桶存放的是指向键值对数据的指针,通过指针找到键值对数据,键值对数据再保存指向实际数据对的指针
# 哈希表结构
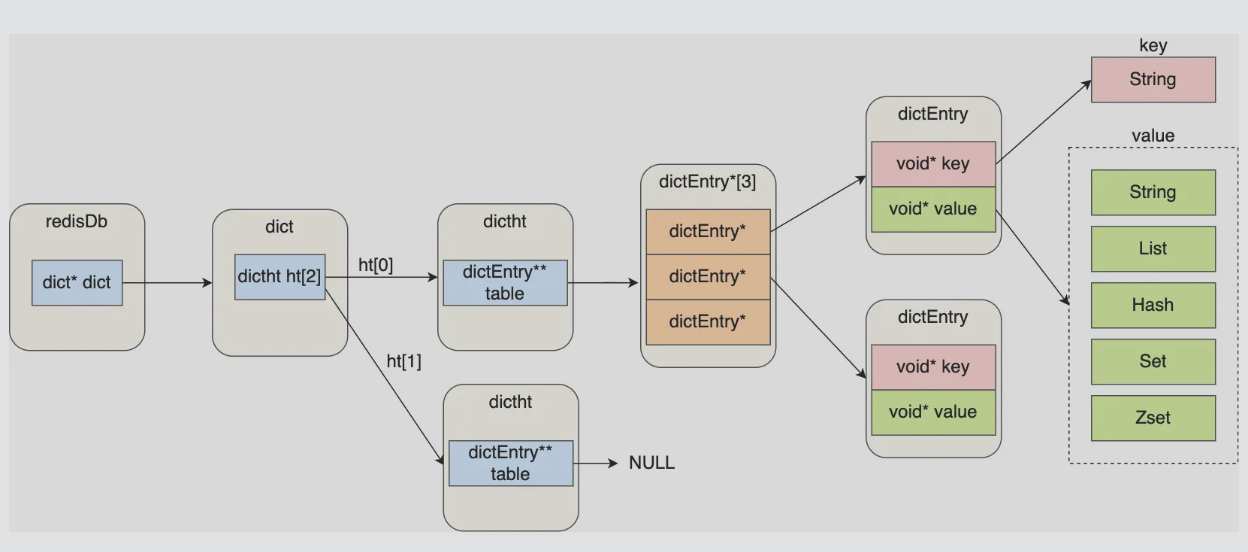
hash数据类型用的是哈希表+listpack实现
哈希表底层用的拉链法解决冲突
typedef struct dictht {
//哈希表数组
dictEntry **table;//一个数组,每个元素指向哈希表节点的指针
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有的节点数量
unsigned long used;
} dictht;
2
3
4
5
6
7
8
9
10
typedef struct dictEntry {
//键
void *key;
//值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
2
3
4
5
6
7
8
9
10
11
12
13
拉链法解决冲突时,长期使用导致一个冲突的哈希桶有太多值,冲突概率增大,因此需要rehash来定期维护哈希表
# rehash
typedef struct dict{
……
//两个哈希表交替使用
dictht ht[2];
}dict;
2
3
4
5
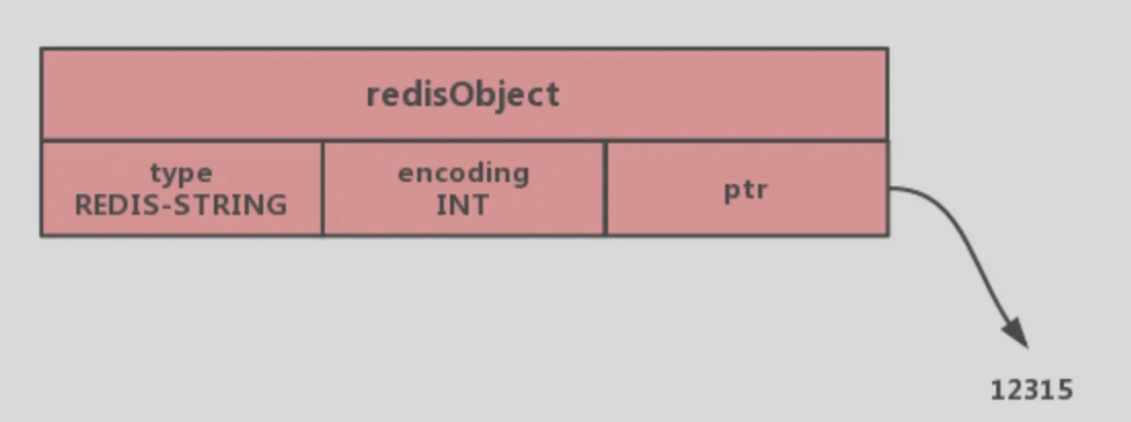
字符串对象的内部编码有三种:int、raw、embstr
# int类型的编码方式
- 保存对象是整数值
- 可以被long类型标识
那么会将整数值保存在字符串对象结构的ptr属性里,编码设置为int
# SDS(simple dynamic string)
来表示string字符串数据类型
c语言字符串的缺陷
- 获取字符串长度的时间复杂度为O(N)
- 字符串不能含有“\0”,即只能放文本数据,不能保存二级制数据
- c语言标准库中字符串的操作函数是不安全、不高效
# SDS结构
//sdshdr8
struct __arrtibute__ ((__packed__)) sdshdr8{
uint8_t len;//实际使用的字符串长度,1字节
uint8_t alloc;//分配的内存大小,1字节,
unsigned char flags;//表示是sdshdr几,1字节,实际只用了3位,
char buf[44];//指向实值,44字节
}//共47字节,
2
3
4
5
6
7
sds分成多种,sdshdr5、sdshdr8、sdshdr16、sdshdr32、dsdhdr64用于存储不同长度的字符串,即len和alloc成员变量的数据类型不同,sdshdr几,代表uint为多少位。sdshdr16,则len和alloc为uint16_t类型。
__arrtibute__ 表示取消结构体在编译过程中的优化对齐,按照实际占用字节数对齐
采用SDS结构的编码方式有两种embstr和raw
# embstr类型的编码方式
专用于保存短字符串
- 保存的是一个字符串
- 字符串长度<=44字节(redis5.0)
将使用简单动态字符串SDS来保存这个字符串,并将对象的编码设置为embstr
字符串对象结构里保存SDS的数据信息,用buf指针指向实值

redisObject结构
struct redisObject{
unsigned type:4;//对象的类型
unsigned encoding:4;//具体的编码方式,embstr、sds
unsigned lru:LRU_BITS;//24位,表示对象最后一次被程序访问的时间,和内存回收有关
int refcount;//引用计数,4字节
void *ptr;//指向对象实际的数据结构,8字节
}//总共16字节
2
3
4
5
6
7
SDS结构sdshdr
struct __arrtibute__ ((__packed__)) sdshdr8{
uint8_t len;//实际使用的字符串长度,1字节
uint8_t alloc;//分配的内存大小,1字节,
unsigned char flags;//表示是sdshdr几,1字节,实际只用了3位,
char buf[44];//指向实值,44字节
}//共47字节,
2
3
4
5
6
redisObject(16) + SDS(47) + 结束符\0(1)=64
sdshdr会分配8,16,32,64字节的内存
# raw类型的编码方式
- 保存的是字符串
- 字符串长度>44字节(redis5.0)
用SDS来保存这个字符串,并将对象的编码设置为raw
ptr指向SDS的数据信息,用buf指针指向实值
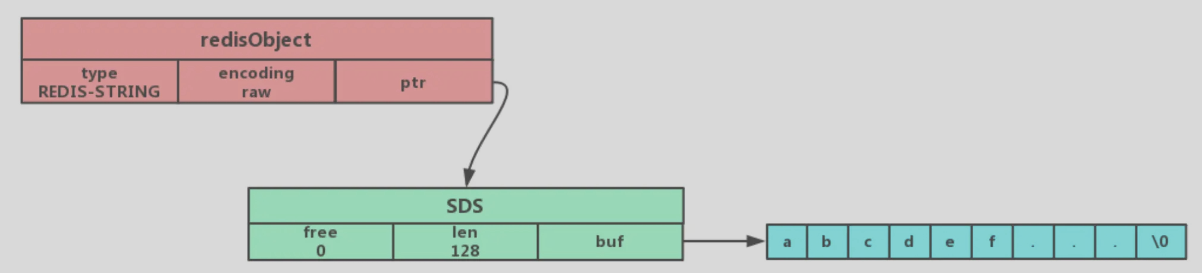
# raw相比embstr
embstr一次分配一块连续的内存空间来保存redisObject和SDS
raw编码通过调用两次内存分配函数来分别分配两块空间来保存redisObject和SDS
embstr优点
- embstr有更少的内存分配和释放次数
- 连续的内存空间有更好的查询效率
embstr缺点
- 字符串长度增加时,redisObject和sds都需要重新分配空间
因此embstr编码的字符串对象实际上是只读的,没有修改它的程序,如果要修改,会将其转为raw再修改
# SDS优点
redis的SDS结构在原本字符数组上,增加了三个元数据来解决c语言字符串的缺陷。
- 二级制安全:SDS为了兼容c标准库函数,依然在结尾加上“\0”字符。同时程序不会对其中的数据做任何限制,数据写入和读取是一样的
- O(1)复杂度获取字符串长度
- 不会发生缓冲区溢出:alloc和len可以计算出剩余空间的大小,自动扩容
# 扩容策略
sds长度小于1MB,翻倍扩容
sds长度超过1MB,依次增加1MB
# 压缩列表ziplist
# 优缺
优点:
- 采用连续的内存空间,利用上了cpu缓存
- 对不同长度的数据采用不同的编码,节省内存开销
缺点:
- 元素的增加会降低查询效率
- 新增或修改元素时内存空间需要重新分配、
- 新增或修改元素可能引发连锁更新
# 结构设计
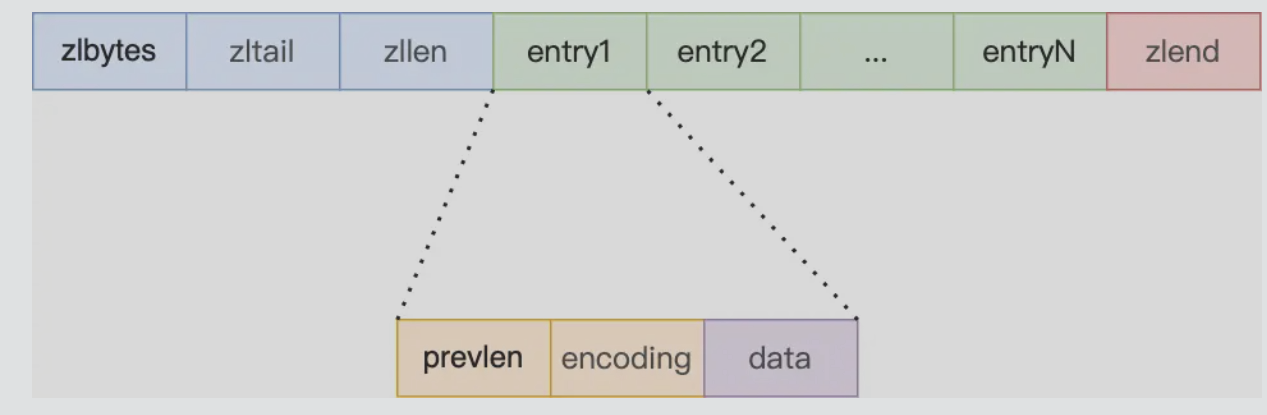
由如下五部分构成
- zlbytes 记录整个压缩列表占用内存字节数
- zltail 记录到表尾的偏移量
- zllen 记录压缩列表包含的节点数量
- entry 实际的值
- zlend 列表的结束点,固定0xFF
entry结构
- prevlen 记录前一个节点的长度,用于从后往前遍历,
- 如果前一个节点长度小于254,则用1字节来保存长度,
- 如果大于等于254字节,用5字节来保存长度
- encoding,记录当前节点实际数据的类型和长度 (字符串和整数)
- data 实际数据
encoding部分和listpack类似
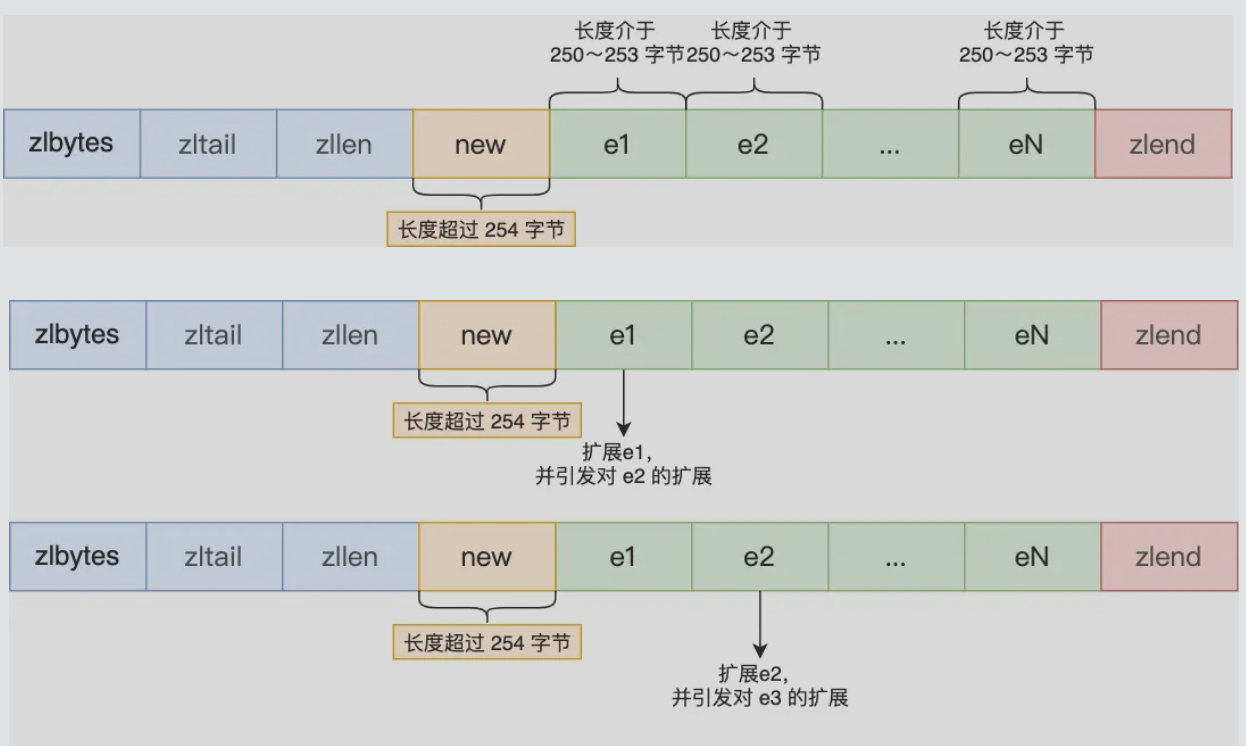
# 连锁更新
新增元素或修改元素时,如果空间不够,压缩列表需要重新分配空间,想象一个压缩列表目前所有元素的长度都是253字节
原本下个元素的上个元素小于254,下个元素用1字节保存长度,
插入一个大元素时,下个元素用5个字节prevlen来保存长度,即下个元素的长度整体扩大了4个字节,超过了254,迫使下下个元素的prevlen字节也要扩容,这样连锁下去
# listpack
# 结构
对于链表,采用跳表,因此用紧凑列表
紧凑列表,用连续的内存空间保存数据,用不同的编码方式保存不同长度的数据,listpack将字符串列表进行序列化存储
**listpack构成:**由四部分组成
- total bytes:表示整个listpack的空间大小,占用4个字节
- num elem:表示元素个数,即entry的个数,占用2个字节,超过2个字节的元素个数也可以存放,只是要遍历整个listpack
- entry为具体的元素
- end为listpack结束标志,1字节,内容为0xFF
entry结构
- 编码类型encoding type
- 数据data
- 前两部分的长度element-tot-len(<=5字节),第一个bit用于标识,0标识结束,1表示未结束,每个字节只有7bit有效
其中data部分的数据如果很短可以放在type字段中
通过element-tot-len可以计算出type和data的总长度从而找到上一个元素的首地址
type编码方式
对于小的数字:用1字节表示
0|xxxxxxx
对于小的字符串:6位字符串长度,后面是字符串内容
10|xxxxxx <string-data>
多字节编码:
110|xxxxx yyyyyyyy //表示无符号整型数据,后5位+下个字节共13bit表示数据
1110|xxxx yyyyyyyy //表示12位长度的字符串,后4位+下个字节用来表示字符串长度,再之和为字符串数据
2
1111|0000 <4 bytes len> <large string>//即32位长度字符串,后4字节为字符串长度,再之后为字符串内容
1111|0001 <16 bits signed integer>//即16位整型,后2字节为数据
1111|0010 <24 bits signed integer>//即24位整型,后3字节为数据
1111|0011 <32 bits signed integer>//即32位整型,后4字节为数据
1111|0100 <64 bits signed integer>//即64位整型,后8字节为数据
1111|0101 to 1111|1110 //当前不用
1111|1111 End of listpack,//结尾标识
2
3
4
5
6
7
@避免连锁更新的实现方式
每个列表只记录自己的长度,不会像ziplist中的列表项那样记录前一项的长度。当在修改或新增元素时,只会涉及每个列表项自己的操作,不影响后续列表项的长度变化,从而避免连锁更新
查询
正向查询:listpack保存了LP_HDR_SIZE,用于吧指针移到第一个entry列表项
- listpack的结构记录了编码类型,从而得知encoding+data的总长度len1
- 通过len1计算出element-tot-len的长度
- len1+element-tot-len之和为entry的总长度len
- 向后移动总长度len即为下应该列表项的起始位置
反向查询:
element-tot-len的第一位为1表示没有结束,左边字节仍然为element-tot-len的内容,第一位为0表示结束,element-tot-len的低7位采用大端模式存储
element-tot-len记录了这个字节的长度,即上个字节的地址
删除
用空元素替换
改和插入
- 计算插入后的整个listpack空间,通过realloc申请空间
- 调整新listpakc中老元素的位置,加入新元素
- 释放旧listpack
- 更新新listpack信息
# 数据类型
支持的数据类型和应用场景:
- String(字符串):缓存对象、分布式锁、共享session信息
- Hash(哈希):缓存对象、例如:购物车
- List (列表):消息队列
- Set(集合):聚合(交并差)计算,例如:共同关注
- Zset(有序集合):排序场景
- Bitmaps(位图):二值状态的统计,例如:签到、判断登录状态
- HyperLogLog(基数统计):例如:网页UV计数(独立访客统计)
- GEO(地理信息):储存地理位置信息的场景
- Stream(流):消息队列
HyperLogLog比起set占用更小空间,仅实现基数统计,对于2^64个不同元素的基数只需用12KB的内存,结果的误差在一定范围内
例如:数据集{1,3,5,7,5,7,8}的基数集为{1,3,5,7,8},基数为5
stream比起list,自动生成全局唯一消息ID,支持以消费组形式消费数据
# string类型
是kv结构,value最多容纳数据512M
底层为SDS(简单动态字符串),相比起c字符串
- SDS可以保存文本数据和二进制数据,使用len属性的值来判断字符串是否结束,包含图片、音视频、压缩文件等
- 获取字符串长度的时间复杂度是O(1)
- SDS的API是安全的,拼接字符串会自动扩容
# 命令
# 设置key-value类型的值
SET name lin
MSET key1 value1 key2 value2
# 根据key获得value
GET name
MGET key1 key2
# 判断key是否存在
EXISTS name
# 返回key所存储的字符串值的长度
STRLEN name
# 删除某个key对应的值
DEL name
# 设置租约为60s
EXPIRE name 60
# 查看数据还要多久过期
TTL name
# 设置key-value类型的值,并设置过期时间
SET key value EX 60
SETEX key 60 value
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 应用场景
1、缓存对象
使用string来缓存对象有两种方式:
直接缓存整个对象的JSON
例:
SET user:1 {“name” : “xiaolin”, “age”:18’}将key分离为属性,采用mset存储,由mget获取个属性值
例:MEST user:1:name xiaolin user:1:age 18
2、常规计数
redis是单线程的,命令的执行为原子的,适用访问次数、点赞等
3、分布式锁
利用当key不存在再插入这个特性可以用它来实现分布式锁
set lock_key unique_value NX PX 10000
- lock_key表示加锁名
- unique_value为客户端生成的唯一标识,用来确认谁加的锁
- NX表示不存在则插入,
- PX表示过期时间为10000
解锁的过程就是将lock_key键删除,注意删除前要先判断下value是当前客户端的唯一标识
解锁过程涉及两个操作因此要用Lua脚本来保证原子性
4、共享session信息
在分布式系统下,用户一的session信息存储在服务器一,第二次访问时被分配到服务器二,这时服务器二没有用户一的session信息,因此需要redis对session信息统一存储管理
将session信息存入redis服务器,多个服务器公用它

# list类型
可以两头写,无顺序,简单字符串列表,最大长度为2^32-1
# 底层实现
底层为双向链表或压缩列表
- 列表的元素<512个(可配置),并且每个元素的值小于64字节,redis会使用压缩列表
- 其他情况用双向链表
redis 3.2之后,全部由quicklist实现
# 命令
# 将一个或多个左值插入key列表的
LPUSH key value [value……]
# 将一个或多个左值插入key列表的
RPUSH key value [value……]
# 移处左边的元素
LPOP key
# 移除右边的元素
RPOP key
# 返回列表指定区间的元素
LRANGE key start stop
# 从key列表表头弹出一个元素,没有旧阻塞timeouot秒,==0则一直阻塞
BLPOP key [key …] timeout
# 表尾弹出
BRPOP key [key …] timeout
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 应用场景
1、消息队列
list 和 stream均可实现
存取消息必须满足:消息保序、处理重复的消息、保证消息可靠性
@ 如何满足消息保序需求
队列先入先出本身能满足消息保序,LPUSH+RPOP(RPUSH+LPOP)
为了生产者能通知消费者,redis提供BRPOP命令阻塞读取,没有读到队列数据时自动阻塞,有新的数据后再读取,比起轮询减少CPU开销
@ 如何处理重复的消息
消费者要实现重复的消息判断
- 每个消息有全局ID
- 消息者要记录处理过的消息ID,重复的不处理
list并不会对每个消息生成ID号,需要程序员在list里包含这个ID
@ 如何保证消息可靠性
消费者从list取出消息,list不会保存这个消息,如果消费者故障,则消息没有处理就丢失了
BRPOPLPUSH命令能让消费者程序从一个list中读消息,同时redis将这个消息插入另一个list备份
@ list存在的缺陷
不支持多个消费者读同一消息
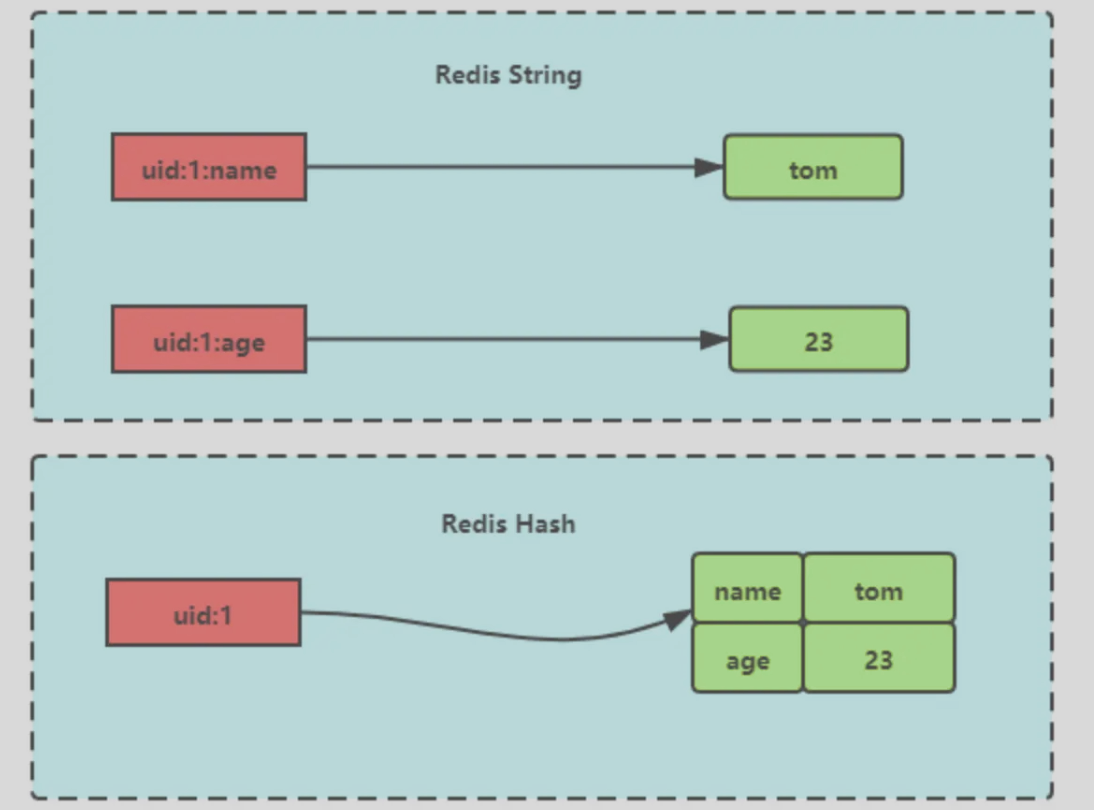
# hash类型
hash是键值对的集合,value=[{field1, value1},……{fieldN, valueN}]
string是一个KV对,hash一个K能存放多个field,对应多个值
# 底层实现
底层为压缩列表或哈希表
- 列表的元素<512个(可配置),并且每个元素的值小于64字节,redis会使用压缩列表
- 其他情况用hash表
redis 7.0后压缩列表替换为listpack实现
# 命令
# 存储哈希表key的键值
HSET key:1 field value # 插入一个(1,field,value)
HMSET key:2 name jerry [age 13 ……] # 插入多个键值
# 获取哈希表key对应的field键值
HGET key field # 获取一个field
HMSET key field [field ……] # 获取多个field
HGETALL key # 返回哈希表key中所有的键值
# 删除key中的field键值
HDEL key field [field ……]
# 返回哈希表key中field的数量
HLEN key
# 为哈希表key中field键的值加上增量n
HINCRBY key field n
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 应用场景
1、缓存对象
(对象id,属性,值)
string+Json也可以存储对象,一般对象中频繁变化的属性可以抽出来用hash储存
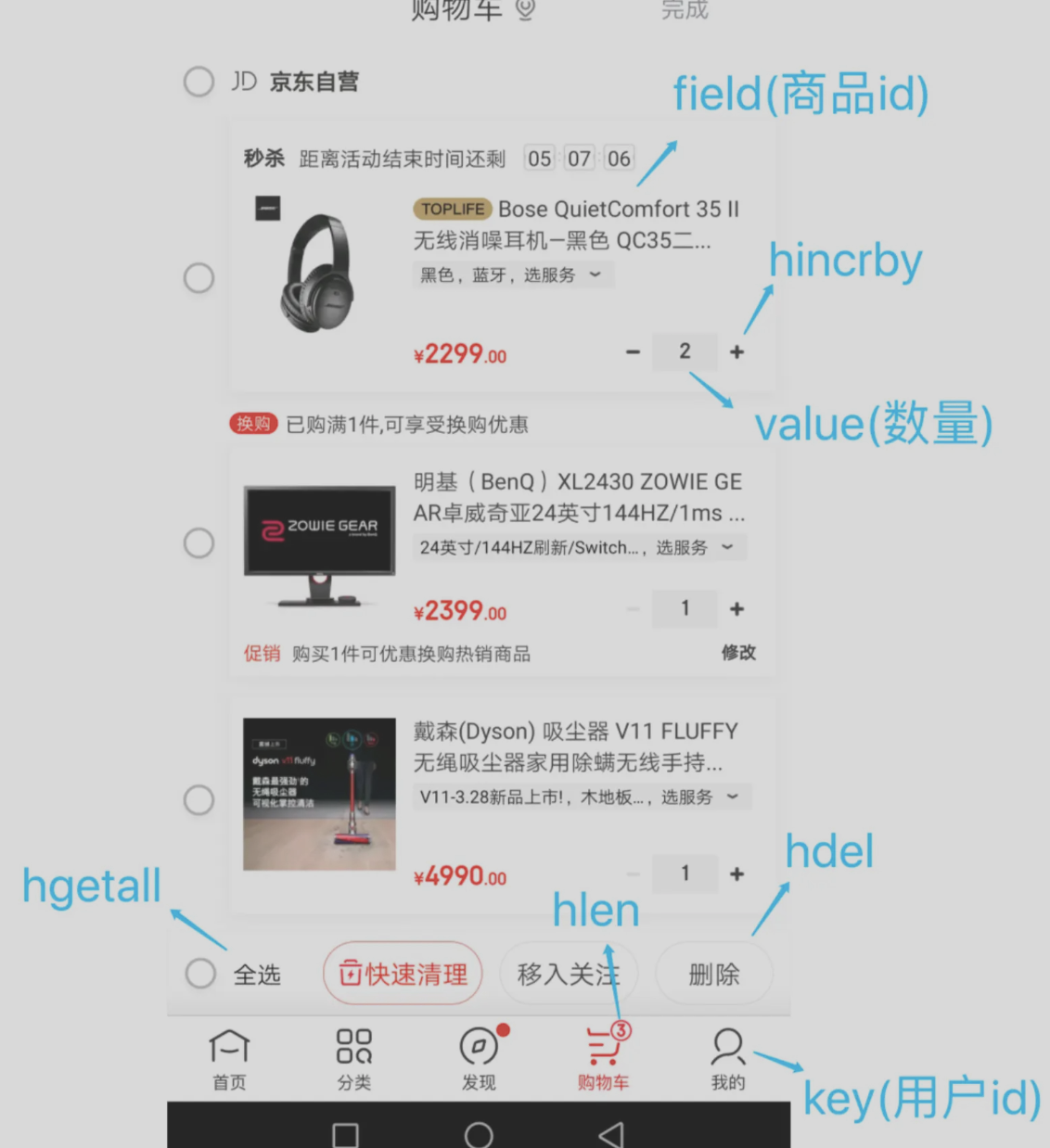
2、购物车
key:(field、value) 对应 用户id:(商品id、数量)
# set类型
无序并唯一的键值集合,最多存储2^32-1个元素,可以支持取交集并集差集
set与list的区别:
- set只能存储非重复元素、list可以存储重复元素
- list是按照元素的先后顺序存储,set无序存储
# 底层实现
底层为哈希表或整数集合
- 列表的元素<512个(可配置),并且每个元素的值小于64字节,redis会使用整数集合
- 其他情况用哈希表
# 命令
# 往集合key中存入元素,存在则忽略,不存在则新建
SADD key member [member …]
# 删除
SREM key member [member …]
# 获取所有元素
SMEMBERS key
# 获取集合key中的元素个数
SCARD key
# 判断member元素是否存在
SISMEMBER key member
# 从集合key中随机选出count个元素,不从key中删除
SRANDMEMBER key [count]
# 从集合key中随机选取count个元素,从key中删除
SPOP key [count]
# 交集运算
SINTER key [key …]
# 求交集并存入新集合destination
SUNIONSTORE destination key [key …]
# 差集运算
SDIFF key [key …]
# 将差集结构存入新集合destination中
SDIFFSTORE destination key [key …]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 应用场景
适用于数据去重和保障数据的唯一性,统计集合交并集等
但set求差并交的计算复杂度较高,容易造成阻塞,因此在主从集合中,可以用从库完成聚合统计、或者返回给客户,客户端完成聚合统计
1、点赞
set能保证一个用户只能点一个赞,例如key是文章id,value是用户id
# 用户123对文章点赞
SADD article:1 uid:1
SADD article:1 uid:2
SADD article:1 uid:3
# 取消了点赞
SREM article:1 uid:1
# 获取所有点赞
SMEMBERS article:1 # 获取所有点赞的人
SCARD article:1 # 获取点赞的用户数量
# 判断用户是否对文章点赞了
SISMEMBER article:1 uid:1
2
3
4
5
6
7
8
9
10
11
2、共同关注
用交集运算计算共同关注的好友、公众号
3、抽奖活动
存储活动中中奖的用户名,确保不会一个用户中奖两次,随机取函数可以用于抽奖
SADD lucky Tom Jerry John Sean Marry Lindy Sary Mark
# 抽取1个一等奖
SRANDMEMBER lucky 1
# 抽取2个二等奖
2
3
4
# ZSet类型
# 底层实现
底层用压缩列表或跳表,比起set多了排序属性,每个元素由两个值构成,一个是排序(score)值,一个是元素值
- 集合的元素<128个(可配置),并且每个元素的值小于64字节,redis会使用压缩列表
- 其他情况用跳表
redis 7.0后压缩列表用listpack实现
# 命令
# 往有序集合key中加入带分值元素
ZADD key score member [[score member]……]
# 往有序集合key中删除元素
ZREM key member [member ……]
# 返回有序集合key中元素member的分值
ZSCORE key member
# 返回有序集合key中元素的个数
ZCARD key
# 为有序集合key中元素member的分值加上increment
ZINCRBY key increment member
# 获取有序集合key从start到stop下标的元素
ZRANGE key start stop [WITHSCORES]# 正序
ZREVRANGE key start stop [WITHSCORES]# 倒序
# 返回指定分数区间内的成员,分数由低到高
ZRANGEBYSCORE key min max [WITHSCORES][LIMIT offset count]
# 返回指定成员区间内的成员,分数必须相同
ZRANGEBYLEX key min max [LIMIT offset count]# 按字典正序排列
ZREVRANGEBYLEX key min max [LIMIT offset count]# 按字典逆序排列
# 并集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积
ZUNIONSTORE destkey numberkeys key [key...]
# 交集计算(相同元素分值相加),numberkeys一共多少个key,WEIGHTS每个key对应的分值乘积
ZINTERSTORE destkey numberkeys key [key...]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 应用场景
Zset类型可以根据元素的权重来排序,面对需要分页展示最新列表(以时间作为权重)、排行榜等场景
排行榜
以博文点赞排名,
对于新增一个点赞,可以用ZINCRBY user:xiaolin:ranking 1 arcticle:4
查看赞数,可以用ZSCORE user:xiaolin:ranking arcticle:4
获取赞数最多的三篇文章,ZREVRANGE user:xiaolin:ranking 0 2 WITHSCORES
电话、姓名排序
# BitMap
位图,适用于数据量大且使用二值统计的场景
# 内部实现
本身用string类型作为底层数据结构,string保存为二进制的字节数组
# 命令
# 设置key表的第offset位,value只能是0或1
SETBIT key offset value
# 获取值
GETBIT key offset
# 获取指定范围为1的个数
BITCOUNT key start end
# 作位运算
BITOP [operations][result][key1][keyn]
# operations:
# AND &
# OR |
# XOR ^
# NOT ~
# result
# 计算的结果存储在该key中
# key1 keyn,为参与运算的key范围,not只能有一个key
# 返回指定key中第一次出现指定value(0/1)的位置
BITPOS [key][value]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 应用场景
签到统计
记录一个用户的签到情况
记录该用户,6月3号(3的下标是2)的签到值为1 SETBIT uid:sign:100:202206 2 1
检查该用户6月3号是否签到 GETBIT uid:sign:100 :202206 2
统计该用户在6月的签到次数 BITCOUNT uid:sign:100:202206
判断用户登录态
对于5000万用户只需6MB空间
连续签到用户统计
统计连续7天打卡用户总数
将每天的日期作为Bitmap的key,userId作为offset,即有7个Bitmap
对这7个Bitmap作与运算,得到的Bitmap对应的offset为1就表示这个用户连续7天打卡了
# HyperLogLog
统计基数的数据类型,非准确统计,基于概率的统计,误算率为0.81%
对于大量的数据的统计所需的内存空间固定且较小,12KB的内存可以算2^64个不同元素的基数
# 使用
# 添加指定元素
PFADD key element [element ……]
# 返回给定的HyperLogLog基数
PFCOUNT key [key ……]
# 将多个HyperLogLog合并为一个HyperLogLog
PFMERGE destkey sourcekey [……]
2
3
4
5
6
# 应用场景
百万级网页UV计数
# GEO
存储地理位置
# 内部实现
使用了Sorted Set集合类型,实现了经纬度到Sorted Set集合中的权重分数的转换
对二维地图作区间划分,并对区间进行编码
# 应用场景
滴滴打车
# stream
专门为消息队列设计的数据类型
传统的消息队列存在一些问题:
- 发布订阅模式不能持久化,对于离线重连的客户端不能读取消息
- list实现消息队列的方式不能重复消费,消费后就会被删除,并且生产者需要自行实现全局唯一ID
@发布订阅模式为什么不能作为消息队列
- 发布/订阅机制没有基于数据类型实现,所以不会写入RDB和AOF中,不具备数据持久化的能力
- 订阅者离线重连后不能消费之前的历史消息
- 消费端有消息积压时,如果超过32M或60s保持8M以上,消费端会被强行断开
所以,发布/订阅机制只适合即时通讯的场景
# 命令使用
# 往message队列中插入消息,键为key,值为value
# *表示生成ID,保证有序并生成全局唯一
XADD message * key value
>1654254953807-0
# XDEL:根据消息ID删除消息
# 读取消息,读取流message里ID为1654254953807-0以后的消息,不包括当前ID
XREAD STREAMS message 1654254953807-0
# 对于阻塞读,读取最新消息,如果没有消息到来,将阻塞10s再返回
XREAD BLOCK 10000 STREAMS message
2
3
4
5
6
7
8
9
10
11
# 应用场景-消息队列
插入成功的数据会返回全局唯一的ID,这个ID第一部分为当前服务器的时间,第二部分为当前ms内的消息序号,从0开始编号
消费组
# 用消息队列message创建一个名为group1的消费组,0-0表示从第一条消息开始读取
XGROUP CREATE message group1 0-0
XGROUP CREATE message group2 0-0
# 只写入一条消息
XADD message * name sonkken
# 读取
XREADGROUP GROUP group1 consumer1 STREAMS message # 可以读到消息
XREADGROUP GROUP group2 consumer2 STREAMS message # 可以读到消息
# 此时再读取group1,group2将读的NULL值
2
3
4
5
6
7
8
9
10
11
12
消息队列中的消息一旦被消费组读取了,就不能再被该消费组的其他消费者读取,但不同消费组的消费这可以消费同一条消息
使用消费组可以让多个消费者分担读取消息
# 让consumer1、2、3各自读取group2的一条消息
XREADGROUP GROUP group2 consumer1 COUNT 1 STREAMS message
XREADGROUP GROUP group2 consumer2 COUNT 1 STREAMS message
XREADGROUP GROUP group2 consumer3 COUNT 1 STREAMS message
2
3
4
@ 如何保证消费者发生故障重启后仍能读取未处理完的消息
streams会自动使用内部队列(PENDING List)留存消费组里每个消费者读取的消息,直到消费者使用XACK命令通知streams消息处理完成
# 查看message中group2的消息个数
XPENDING message group2
# 查看消费者具体读了哪些数据
XPENDING message group2 - + 10 consumer2
#用XACK命令通知streams删除消息
XACK message group2 xiaoxiID
2
3
4
5
6
7
@ stream消息会丢失吗
在生产者和消费者部分不会丢失消息,在中间件部分会丢失:
- AOF持久化配置为每秒写盘,这个过程是异步的,redis宕机时可能丢失数据
- 主从复制也是异步的,主从切换时可能丢失数据
像RabbitMQ或Kafka这类专业的队列中间件,生产者发布消息时,中间件会写多个节点,一个节点挂了集群数据不丢失
@stream消息可堆积吗
redis作为内存数据库,消息积压超过内存上限会面临OOM风险,所以redis的stream提供指定队列最大长度的功能,超过上限时,旧消息会被删除
因此将redis作为消息队列使用可能面临:
- redis的数据丢失
- 面对消息挤压,内存资源紧张
因此如果业务简单,可以使用,但如果业务有海量消息,不能接收数据丢失,应该用专业的消息队列中间件
# redis线程模型
redis的线程:
主线程完成:接收客户端请求->解析请求->数据读写->发送给客户端
bio_close_file线程:处理关闭文件
bio_aof_fsync线程:负责AOF刷盘
bio_lazy_free线程:来释放redis内存
redis 6.0后引入三个I/O多线程: io_thd_1、io_thd_2、io_thd_3:
即,默认情况下加上主线程有7个线程
后台线程的任务操作都很耗时,因此有单独的线程完成
生产者把耗时任务丢到任务队列中,后台线程相当于消费者轮询队列处理
# redis单线程模式
redis 6.0之前的单线程模式
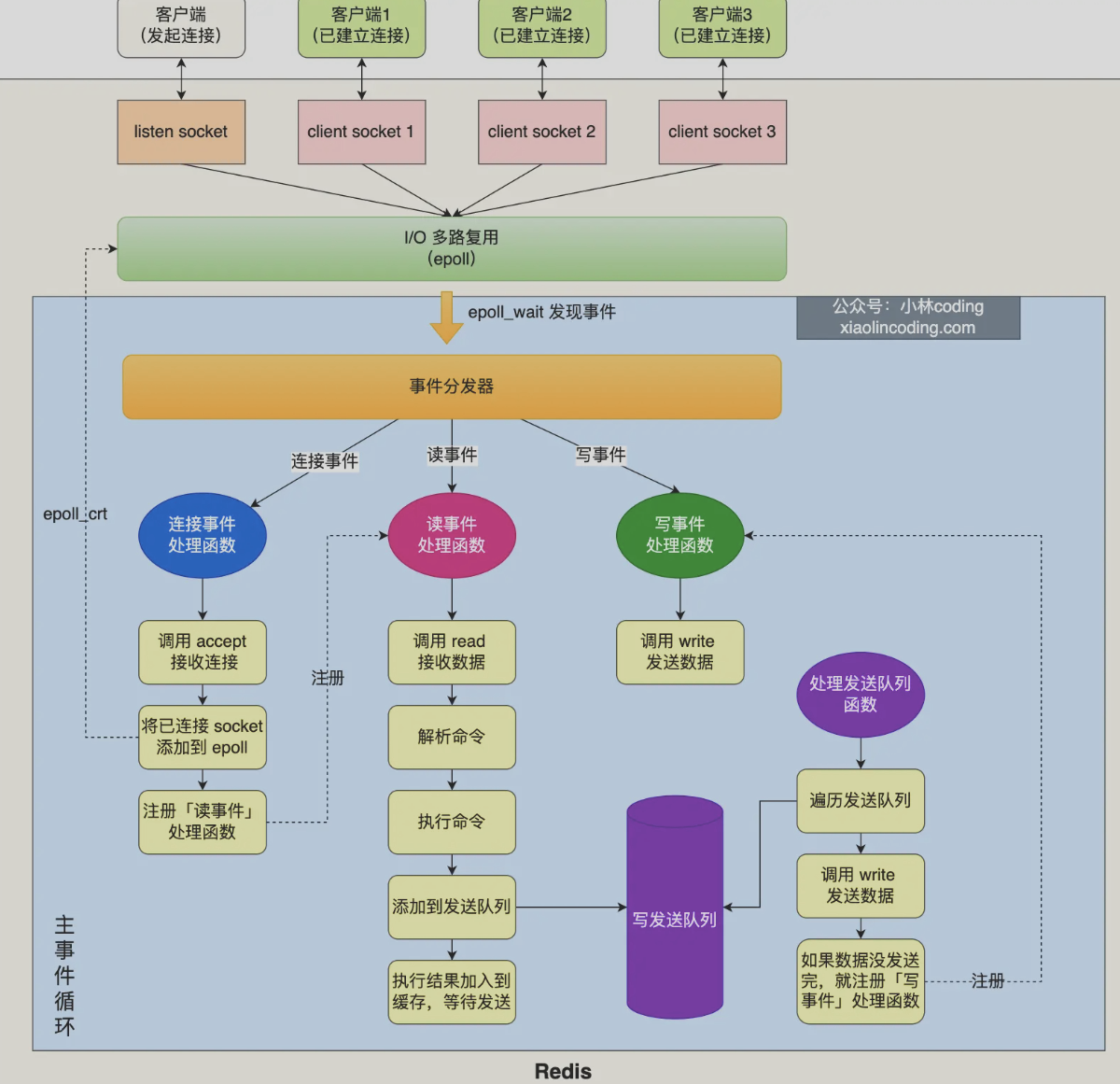
通过epoll接收客户端的相应,事件分发器生成对应的连接事件、读事件、写事件,主线程做事件循环依次处理事件
# 事件循环函数
调用处理发送队列函数:对于这一轮,如果有发送任务,通过write函数将客户端缓冲区的数据发送出去,如果没有,注册写事件处理函数,epoll_wait函数发现事件后再处理
接着,调用epoll_wait函数等待事件
- 对于连接事件,调用连接事件处理函数
- 调用accpet获取已连接的socket
- 调用epoll_ctl将已连接的socket加入到epoll
- 注册读事件处理函数
- 对于读事件,调用读事件处理函数
- 调用read获取发来的数据
- 解析命令
- 处理命令
- 将客户端对象添加到发送队列
- 将执行结果写入发送缓存区
- 对于写事件,调用写事件处理函数
- 通过write函数将客户端发送缓存区的数据发送出去,
- 如果这一轮数据没有发完,继续注册写事件处理函数,等待epoll_wait发现后再处理
# redis为什么使用单线程
redis吞吐量可以达到10W/s
redis的单线程为什么快
- 大部分操作在内存中完成+高效的数据结构
- 单线程模型避免了多线程的竞争和切换开销
- I/O多路复用机制
redis 6.0前为什么用单线程
redis的性能瓶颈并不是CPU,更多时候是内存大小和网络I/O的限制,因此采用单线程即可(多线程会使得CPU性能过剩)
如果要使用多线程,则可以在一台服务器上启动多个节点或采用分片集群
单线程易于维护,不会产生并发读写的问题,不会有线程切换竞争等损耗
# 为什么引入了多线程
网络硬件性能的提升使得redis的性能瓶颈有时在网络I/O的处理上
redis 6.0用多线程处理网络I/O,对于命令依然是单线程处理
可以通过配置文件修改多线程的使用,默认只针对发送响应数据,不会以多线程的方式处理读请求
线程的数量,官方建议是小于机器核数,8核则分配6个线程即可(加上主线程7个)
# 持久化
# 主要实现方式
- AOF日志:每执行一条写操作,将命令以追加的方式写入到一个文件里
- RDB快照:将某一时刻的内存数据以二进制的方式写入磁盘
- 混合持久化方式:结合上面两种
# AOF日志
每执行一条写操作,将命令追加写入一个文件,文件内容
# AOF日志格式

*3 表示当前命令有三个部分
$数字 表示一个部分的开头,后面跟着命令\键\值,数字表示这部分的有多少字节
@ 为什么先执行命令,再写入
- 先记录再执行,如果执行失败(语法失败),那么用日志恢复时就会出错
- 单线程执行,不会阻塞写操作的执行
@ 带来的风险
- 数据可能丢失
- 单线程执行,可能阻塞其他操作
# AOF写回策略
执行写操作命令,将命令追加到server.aof_buf缓冲区,IO系统调用write,写入内核缓冲区的AOF文件,内核发起写操作进入硬盘
redis的三种写回硬盘策略
- Always:每次写操作都同步AOF到硬盘
- everysec:每次写操作后都写入AOF内核缓冲区,每隔一秒写到硬盘
- NO:不由redis控制写硬盘的时机,os决定
# AOF重写机制
AOF日志过大时会带来性能问题,恢复很慢
因此当AOF文件大小超过设定的阔值后,启动AOF重写机制,压缩AOF文件
原理:在重写时,读取当前数据库中的所有键值对,将每一个键值对用一条命令记录到新的AOF文件,全部记录完成后,用新的AOF文件替换掉旧的AOF
例如:
旧文件先后执行了[set name xiaolin] 和 [set name xiaolincoding]这两个命令
重写机制后,合为一条命令[set name xiaolincoding]
重写AOF日志的过程
重写过程由后台子进程bgrewriteaof来完成,而不是线程,这样做的优势:
使用多个线程对共享内存的修改会涉及到加锁,降低性能, 而子进程以只读的方式共享父进程的数据,当父子进程任意一方修改了该共享内存就会发送写时复制,不需要加锁
触发重写机制后,重写子进程以只读的方式读取数据库里的所有数据,逐一把内存数据的键值对转换为一条命令,再将命令记录到新的AOF
@ 对于重写过程中,主进程的记录修改如何记录到新的AOF?
redis采用了AOF重写缓冲区,创建了bgrewriteaof子进程后开始使用,当redis执行完一个写命令后,会同时将这个写命令写入到AOF缓冲区和AOF重写缓冲区
在bgrewriteaof子进程执行AOF重写期间,主进程需要执行以下三个工作:
- 执行客户端发来的命令
- 将执行后的写命令追加到AOF缓冲区
- 将执行后的写命令追加到AOF重写缓冲区
子进程完成AOF重写规则后,向主进程发送信号
主进程收到信号后:
- 将AOF重写缓冲区的所有内容追加到新的AOF的文件
- 新的AOF文件进行改名,覆盖现有的AOF文件
# RDB快照
对于故障恢复,AOF以记录操作命令的方式恢复数据比较缓慢
RDB记录某一瞬间的内存数据,恢复时直接将RDB文件读入内存即可,恢复数据效率较高
# 快照的线程阻塞机制
redis提供了三种方案决定以什么样的方式执行快照记录
- save命令,将在主线程生成RDB文件,写入时间过长会阻塞线程
- bgsave命令,创建子进程来生成RDB文件,避免主线程阻塞
- 通过配置文件的选项来实现隔一段时间自动执行依次bgsave命令
redis是全量快照,每次执行都是把内存的所有数据记录到磁盘中,所以如果频率太频繁会对性能有影响
@ RDB在执行快照时数据能修改吗
依托写时复制技术,可以边记录边修改,即父子进程的实现机制
# 混合持久化
RDB恢复数据快,但快照的频率不能太高,使得安全性较低,AOF丢失数据少但数据恢复不快
开启了混合持久化时,在AOF重写日志时,重写子进程会先将与主线程共享的内存数据以RDB方式写入到AOF文件, 此时主线程处理的操作记录记录到重写缓冲区里,重写缓冲区里的增量命令以AOF方式写入到AOF文件, 写入完成后通知主进程将RDB格式和AOF格式的AOF文件替换旧的AOF文件
即混合持久化生成的文件,前半部分是RDB格式的全量数据,后半部分是AOF格式的增量数据
优点:恢复速度很快,丢失更少的数据
缺点:AOF中添加了RDB格式使得可读性变差、兼容性差,不能用于redis以前的版本
# redis集群
# 主从复制
将一台redis服务器同步数据到多台服务器上,主从服务器间采用读写分离
主服务器进行读写操作,写操作自动将写同步给从服务器,从服务器一般只读
主从服务器的同步过程是异步的:
主服务器收到新的写命令后,发送给从服务器,然后就向客户端返回结果了,因此主从服务器间的数据不一致,即属于ap
# 哨兵模式
当redis的主从服务器出现故障时,需要手动进行恢复,为解决这个问题增加了哨兵模式,可以监控主从服务器,提供主从节点故障转移的功能
# 切片集群模式
当redis缓存数据量大到一台服务器无法缓存时,使用集群模式将数据分布在不同的服务器上,以降低对单节点的依赖,从而提高读写性能
redis cluster采用哈希槽来处理数据和节点之间的映射关系,一个切片集群有16384个哈希槽(2^14),每个键值对都会根据它的key映射到一个哈希槽中:
- 根据键值对的key,按照CRC16(循环冗余校验)算法计算一个16bit的值
- 再用16bit值对16384取模,每个模数代表一个编号的哈希槽
哈希槽与具体redis节点的映射关系:
- 平均分配:自动把哈希槽平均分布到集群节点上
- 手动分配:手动建立节点间的连接,组成集群,指定每个节点上的哈希槽个数
手动分配时,需要把16384个槽全部分配完
@ 什么是集群脑裂(双主现象)
如果主节点A网络发生问题与所有从节点失联,和客户端网络正常,此时客户端的数据写入只缓存到了主节点A,无法同步给从节点
脑裂引发的数据丢失问题
哨兵发现主节点A失联,重新选举出一个leaderB,然后网络突然好了,旧主节点A降为从节点,从节点A向新主节点请求数据同步,第一次为全量同步,此时节点A清空字节的本地数据,从而之前客户端写入A的数据丢失
@ 解决脑裂引发的数据丢失问题
客户端向主节点的写请求,主节点必须满足如下两个条件:
- 主节点必须有x个从节点连接,小于这个数会禁止写
- 主从数据复制和同步的延迟不能超过x秒,超过会禁止写
如果不满足会直接返回错误给客户端
# 过期删除策略
对key设置过期时间,redis会把key带上过期时间存储到一个过期字典
当查询key时,redis会先检查这个key是否存在于过期字典中
不在,正常读值,在,则获取过期时间,与当前系统时间进行对比,判定是否过期
redis使用的过期删除策略是惰性删除+定期删除
# 惰性删除策略
不主动删除过期键、每次从数据库访问key时,检测key是否过期,过期则删除该key
优点:占用系统最少的资源,性能好
缺点:过期key留在数据库中,一直不被访问,造成了内存空间的浪费
# 定期删除策略
每隔一段时间随机从数据库取出一定数量的key进行检查,删除过期key
定期删除的流程:
- 从过期字典中随机抽取20个key检查是否过期,删除过期的key
- 如果过期的数量超过5个(1/4),则重复步骤1
- 如果过期数量小于1/4则停止,等待下一轮再检查
为保证不循环过度,增加了定期删除循环流程的时间上限为不超过25ms
优点:控制删除的时长和频率,来减少删除操作对CPU的影响
缺点:难以确定删除操作执行具体的时长和频率,需要在CPU和内存占用作权衡
# 持久化时,对于过期键如何处理
# RDB文件
对于RDB文件生成阶段:
从内存状态持久化为RDB时,会对key进行过期检查,过期的键不会被保存到新的RDB文件中
对于RDB加载阶段:
如果redis是主服务器运行模式,载入RDB文件时,程序会对文件中保存的键进行检查,过期键不会被载入到数据库中
如果redis是从服务器运行模式,载入RDB文件时,不论键是否过期都会载入。但主从服务器在进行数据同步时覆盖了从服务器的数据,所以不会造成影响
# AOF文件
对于AOF写入阶段:
如果某个过期键还没被删除,会保留次过期键,过期键删除后会向AOF追加DEL命令来显式的删除该键值
对于AOF重写阶段:
会对redis中的键值进行检查,已过期的键不会被保存到重写后的AOF文件
# 主从模式中,对过期键的处理
从库不会过期扫描,主库在key到期时往AOF文件里增加一条del指令,同步所有从库,从库通过执行这条del指令来删除过期的key
# 内存淘汰机制
当运行内存达到了阔值,就会触发内存淘汰机制
不进行数据淘汰:运行内存超过最大设置则不再提供服务
进行数据淘汰:
对设置了过期时间的数据中进行淘汰:
- 随机淘汰设置了过期时间的任意键值
- 优先淘汰更早过期的键值
- 淘汰所有设置了过期时间的键值中最久未使用的LRU
- (默认)淘汰所有设置了过期时间的键值中最少使用的LFU
对所有数据范围内进行淘汰:
- 随机淘汰任意键值
- 淘汰整个键值中最久未使用的键值LRU
- (默认)淘汰整个键值中最少使用的键值LFU
# 删除策略
对于一些key设置了过期时间,使用惰性删除+定期删除的删除策略
定时删除:(redis没有)每个数据都定时一个删除任务
**惰性删除:**每次数据库访问key时,检查是否过期,过期删除(性能好,但没有及时删除,有内存浪费)
**定期删除:**定时检查一定数量的key执行删除
- 随机抽20个key检查并执行过期删除
- 过期的数量超过1/4,则重复步骤1,否则停止
- 循环上限不超过25ms
持久化为RDB文件或通过RDB文件加载时,会对每个键作过期检查
持久化AOF文件,删除操作会追加一条删除命令写入
从库通过主库发出的del命令执行删除
# LRU算法(redis4.0前使用)
利用链表实现最近最少未使用的数据,存在两个问题:
- 链表的管理有额外开销
- 数据被访问需要移动链表,大量的移动会带来很多链表的移动操作,降低性能
redis的实现在对象结构体添加一个额外字段,用于记录此数据的最后一次访问时间
当redis进行内存淘汰时,随机取5个值,淘汰最久没有使用的那个
优点:不用维护链表,节省了空间占用 | 不同每次访问都移动链表,提升了性能
缺点:无法解决缓存污染,一次读取大量数据造成的
# LFU算法(redis4.0后默认)最近最不常用
根据数据访问次数来淘汰数据,增加关键字来记录数据访问频次
typedef struct redisObject {
...
// 24 bits,用于记录对象的访问信息
unsigned lru:24;
...
} robj;
2
3
4
5
6
7
在LRU算法中,lru字段用于记录key的访问时间戳 在LFU算法中,lru字段,高16位用来记录key的访问时间戳,低8位存储logc,记录访问频次
# redis缓存设计
redis作为缓存数据库直接在内存运行,有更高的查询效率,避免直接在磁盘访问
为了保证缓存的数据和数据库中的数据一致性,会给redis的数据设置过期时间,过期后,用户访问的数据如果不在缓存里,业务系统需要重新生成缓存,因此会访问数据库,将数据更新到redis里,后续请求可以直接命中缓存
# 缓存雪崩
当大量缓存在同一时间过期时,面对大量的用户请求,需要大量直接访问数据库,从而增大数据库压力,进一步会造成数据库宕机
解决:
- 随机打散缓存失效时间:在原有的失效时间上增加一个随机值
- 设置缓存不过期:通过后台服务来更新缓存数据
# 缓存击穿
缓存击穿可以是缓存雪崩的子集
有时有几个数据会被频繁访问,例如秒杀活动,这类数据被称为热点数据
如果热点数据过期了,大量的请求访问了该热点数据,无法在缓存中命中,直接访问数据库从而使得数据库很容易被冲垮
解决:
- 互斥锁保证同一时间只有一个业务线程请求数据库
- 不给热点数据设置过期时间,由后台异步更新缓存,在热点数据要过期前,通知后台线程更新缓存即重新设置过期时间
# 缓存穿透
用户访问的数据既不在缓存,也不在数据库中,此时无法构建缓存数据,当大量的这样的请求到来,造成数据库压力增大
通常原因:
黑客恶意攻击,故意大量访问读取不存在的数据
业务误操作,将数据库中的数据误删除了
解决
- 非法请求的限制:判断请求参数是否合理
- 设置空值或者默认值:对查询的数据设置空值或默认值,后续查询从缓存中取到空值
- l使用布隆过滤器快速判断数据是否存在,避免查询数据库:
# 如何设计动态缓存热点数据
对于一些key设置了过期时间,使用惰性删除+定期删除的删除策略
定时删除:(redis没有)每个数据都定时一个删除任务
**惰性删除:**每次数据库访问key时,检查是否过期,过期删除(性能好,但没有及时删除,有内存浪费)
**定期删除:**定时检查一定数量的key执行删除
- 随机抽20个key检查并执行过期删除
- 过期的数量超过1/4,则重复步骤1,否则停止
- 循环上限不超过25ms
持久化为RDB文件或通过RDB文件加载时,会对每个键作过期检查
持久化AOF文件,删除操作会追加一条删除命令写入
从库通过主库发出的del命令执行删除
改进的LRU机制
通过缓存系统作排序队列,最近访问的越靠前,存放最常访问的1000个商品
定期过滤队列后200个,从数据库随机取200个加入队列
请求到达,先取商品ID,命中就根据ID从另一个缓存数据结构中读取实际的商品信息
# 常见的缓存更新策略
# Cache Aside(旁路缓存)策略
实际中redis和mysql都使用这个策略
对于写
先更新数据库的数据,再删除缓存的数据
不能反过来,先删缓存再更新数据库会找出读写并发时出现缓存和数据库不一致
- B读取数据a,缓存没命中,请求查询数据库
- A想更新数据a,删除缓存
- B得到a的旧值加入缓存
- A更新数据库的数据为新值,
- 此时缓存的数据和数据库的数据不一致,将一直保持下去直到缓存失效
而先更新数据库再删除也会出现,但概率不高
- B读取数据a,缓存没命中,请求查询数据库,得到旧值为20
- A想更新数据a,更新数据库为21
- A更新完数据库,删除缓存
- B将旧值写入缓存
对于步骤3和4,通常更新数据库比缓存的写入要慢,所以通常步骤4会先于步骤3发生
如果要彻底解决这个问题:
- 更新值前加分布式锁,同一时间只允许一个线程更新,这会带来写入性能问题
- 给缓存上租约,即使出现缓存不一致,也会很快过期,对业务的影响可接收
对于读
命中缓存则返回,没命中则从数据库读数据再写入缓存
该策略适合读多写少,不适合写多的场景,写入频繁会使得缓存的数据频繁改变,从而缓存命中率低
# Read/Write Through(读穿/写穿)策略
应用程序只和缓存交互,缓存和数据库交互
对于读
查询缓存数据是否存在,存在则返回,不存在则由缓存组件从数据库查询,并写入缓存组件,缓存组件将数据返回给应用
对于写
先查询数据在缓存中是否存在,如果存在则更新缓存数据并同步更新数据库,然后缓存组件返回更新完成 如果不存在,更新数据库后返回
开发中使用较少,因为常用的分布式缓存组件,例如memcached和redis都不提供和数据库交互的功能,对于我们自己写本地缓存可以使用这种策略
# Write Back(写回)策略
更新数据时只更新缓存,将缓存数据设置为脏并返回,不会更新数据库。对于数据库的更新会通过批量异步的方式进行
这种方式常用于计算机体系结构中的设计,如CPU的缓存、os中文件系统的缓存
适用写多的场景,但数据不是强一致性的,并且如果断电有数据丢失的风险
# redis实战
# 如何实现延迟队列
将当前要做的事情推迟一段时间再做,
- 淘宝下单超过一定时间未付款订单自动取消
- 外卖商家10分钟没有接单会自动取消订单
使用有序集合ZSet的方式来实现延迟消息队列,其中有score属性来存储延迟执行的时间
# 对于大key如何处理
即key对应的value很大,例如:
- string类型的值大于10KB
- hash、list、set、zset类型的元素个数超5000个
大key会带来的问题
- 客户端超时阻塞,单线程的redis操作大key比较耗时,造成redis阻塞
- 引发网络阻塞, 如果大key的大小为1M,每秒访问量为1000,对于千兆网卡来说难以应对
- 内存分布不均,集群模型在slo分片均匀情况下,出现数据和查询倾斜,部分大key的节点占用内存多
如何找到大key
redis-cli -h 127.0.0.1 -p6379 -a "password" -- bigkeys
这个命令会占用较多CPU,因此最后在从节点上运行,避免阻塞主节点。同时在业务压力低峰节点扫描检查
只能返回每种类型中最大的bigkey
对于集合类型,只能统计元素个数,不能统计每个元素的大小
用sacn命令查找,用rdbtools工具查找
如何删除大key
删除会释放这个内存空间,os会将其插入空闲内存块的链表,这个过程比较耗时,会阻塞当前释放内存的应用
- 分批次删除
对于hash,用hscan每次获取100个字段,再用hdel每次删除一个字段
- 异步删除
用unlink代替del
也可以通过配置在一些场景下开启自动异步删除
- lazyfree-lazy-eviction : 当运行内存超过maxmeory开启
- lazyfree-lazy-expire:对于设置了过期时间的键值,过期之后是否开启
- lazyfree-lazy-server-del:一些指令内存实现带有隐式的del操作(比如rename),在这种场景下是否开启
- slave-lazy-flush:从节点作数据同步时,在加载master的RDB文件时,会先清理自己的数据,在时是否开启
# redis管道的作用
管道是客户端提供的批处理技术用于一次处理多个redis命令,将多个命令整合到一起发送给服务端处理后统一返回。要避免发送的命令过大而阻塞网络
# redis事务支持回滚吗
没有提供回滚,事务的执行,对于已经正确执行的部分,当当前事务终止,不能回退正确执行的部分,即并不保证事务的原子性
原因是,redis事务的执行一般不会发生错误,通常错误都是由编程错误导致,而非实际应用出现,不需要增加这个功能
同时事务回滚这种复杂的功能违背了redis追求的简单高效
# redis实现分布式锁
用string类型存放锁,需要满足三个条件
- set命令带上nx选项来实现读取并写入锁值
- 锁要设置过期时间,避免客户端拿到锁后发生异常导致锁一直无法释放,EX/PX选项
- 锁变量要能区分不同客户端的加锁操作
set lock_key unique_value NX PX 10000
对于解锁,需要先比较客户端unique_value的值再修改值,这个过程使用Lua脚本保证操作的原子性
优点:
- 性能高效
- 实现方便
- 避免单点故障(redis是跨集群部署的)
缺点:
超时时间不好设置,过长影响性能,过短无法保护到共享资源
可以基于续约的方式设置超时时间,启动应该守护线程,在一段时间后重置这个锁的超时时间,主线程执行完后,终止这个守护线程
主从复制模式中的数据是异步复制的,这将导致分布式锁的不可靠。如果主节点获取到锁后没有同步到其他节点时redis主节点宕机了,此时新的redis主节点依然可以获取锁
@红锁:
为了解决集群下分布式锁的可靠性问题,redis提供了分布式锁算法redlock(红锁)
官方推荐部署5个redis主节点,均为孤立节点,让客户端和多个独立的redis节点依次请求申请加锁,如果过半能完成加锁操作就认为能够加锁,否则加锁失败
redlock算法加锁的三个过程
- 客户端获取当前时间t1
- 客户端按顺序依次向N个redis节点执行加锁操作,同时加锁操作设置一个时间上限(避免某个节点发生故障时,redlock依然能正常运行,通常为几十ms)
- 如果过半获取到了锁,再获取当前时间(t2),计算整个加锁的总耗时(t2-t1),
- 如果获取锁的总耗时小于锁设置的过期时间,并且剩下的时间能够完成数据的操作则成功获取到了锁,否则认为锁过期
- 如果加锁失败,客户端向所有redis节点发起释放锁的操作

